Abstract
The Revolution in publishing is over. The old "send it to the printer and you're done" world is gone. Now we will have multiple versions of documents, that we will maintain (modify) over time. Our task is to provide essential pieces of the infrastructure to support the new era of publishing. This paper proposes a "platform" and an infrastructure, and discusses how best to position HTML.
What's an information choreographer?
Mainly a tongue-in-cheek response to the popular "architect" job-title. My business is about scripting the flow of information, not just building structures to hold and interact with it.
Why a manifesto?
Yes, we are already in the new era; the revolution is over. As in all revolutions, the major effort comes afterward, changing existing infrastructure (and ways of thinking) to the new regime. This is why we are here.
The revolution was as profound as the printing press: there is no longer a single distribution medium (a book on paper), but rather, distribution may take many forms, of which any number may be beyond the control of the publisher. A normative value inherent in infromation -- access -- insists that websites be accessible to lowest common denominator devices: a cellphone, a PDA, Lynx on a computer in a library, a fancy laptop trapped in a bandwidth-impaired Prague hotel room.
It isn't just that everyone can afford a "printing press" (access to a web server). It's also that the publisher no longer controls the output. Yes, we can spec fonts and colors, but it will be to little avail if the user has a sixteen color monitor and Lynx. Perhaps a more subtle version of this point needs to be made: even in a pdf file, brilliantly subtle use of color may just be ridiculously unreadable when printed on a black and white laserprinter.
1) no control of the medium -- the display, processing power, and bandwidth
2) the normative value of "access" to information -- no matter what the user's device is
3) the resultant need for multiple user-interfaces to the same content
4) the never-ending publishing model -- maintaining content over time
5) the advantages of tailoring the content for different users
Note that with desktop publishing, the cost of creating camera-ready copy fell, and control moved closer to the designer. But distribution still required a printing press, and access was still a matter of geography and moving paper around (and paying for the transportation). The economics of information was still tied to the economics of printing and distributing the atoms.
The web removes the need for the printing press, and removes the need to transport atoms. The cost of reproducing information becomes approximately zero. Rather than buying our atoms as a delivery mechanism, consumers now provide their own devices.
And there-in lies the rub.
The web also removes the publisher's control over the presentation. We no longer get to choose the paper and exact colors. No matter what tags we put in the source, users may still look at our sites through sixteen shades of gray on a four-line monitor of a cellphone (or someday a toaster-oven).
Information is power. The network decentralizes information. Ultimately, we are in the business of reshaping the use of power on the planet.
In the meantime, though, if we are running a transaction site, our users may want to make their transactions (buy and sell stocks, for example) from any hardware/software/bandwidth situation they might find themselves.
An advertising-supported website needs all the "hits" it can get. It's a bad idea, then, to make information inaccessible to anyone who wants it.
Similarly, a website to distribute either marketing or technical support information to existing or potential clients, it would be silly for me to demand that they have some arbitrary hardware/software/bandwidth before they can get the information I need to give them in order to make a sale or keep an existing customer satisified.
Before web "designers" there was a phrase: "the customer is always right"....
We need/want three versions of the user-interface. First, a low-bandwidth, very plain version. Second, a still-HTML version that looks pretty. Third, a whiz-bang version with all the bells and whistles we can throw down a wide pipe. We want the cutting-edge version, because we want to take advantage of extra value. We need a pretty, but basically simple version for the masses of people without fast connections and the lastest hardware and software. And we need the very basic version for people with antique desktop computers, or cutting-edge PDAs, or who are on the road in bandwidth-poor areas (no matter how fancy a system they have).
We might also want to use the same source files to generate a book and pdf files in both color and black & white.
This started, let's say, with online help. We had been shipping manuals. Then we needed to provide online help, but it had to be slightly different.
We might now want to generate distinct versions of a website for experts and novices. These different versions of the content need to be maintained in a single set of source files, or we just won't be able to afford to keep it up.
Maintaining two separate versions of information doesn't just double the work: you maintain each version, and then you have to verify that you are maintaining them consistently.
In other words, you lose if you don't automate the generation of the different content versions.
Time was you would finish a document in Pagemaker, send it off to the printer, and that would be the end.
It's different now. Documents now become "assets" that are worth maintaining over time. Even press releases are sent out, then touted on the website, then archived on the website. What happens when you launch a new "look and feel" for the website? You must republish the archives with the new user-interface! It never ends.
So now we need a publishing infrastructure that makes maintaining the content easy, and completely separates the content from the user-interface....
The business of tweaking every pixel a la Quark Express is doomed for two reasons: it's too much work to maintain multiple versions over time, and it requires pretending that you control the display device, and (generally) just refusing to play with anyone who doesn't have the "right" display device.
HTML's popularity has boomed. SGML? HTML is easy to work with for content markup (as opposed to page layout...). HTML's DTD has been routinely flouted by the browser companies. Most HTML authors don't know what a DTD is. At least one leading web design firm distributes templates as "HTML 3.0 Final". Huh?
A product trying to encapsulate the extent of the revolution must be monolithic. As with source control, a product won't help you if you don't follow the "rules". If you do follow the rules, the product is just a convenience. Sometimes I think products in the web market are most valuable as (expensive) educational tools to force people to work a new way.
Databases developed to prevent access to small numbers that are summarized mathematically (accounting systems). It is awkward to try to fit hierarchical information in large blocks into them. It can be done, of course. Again, one could distinguish between information management processes and products: ASCII files stored in a directory structure with good source control is a great way to deal with large amounts of text.
With all the computer resources available, and our great information management skills, is "#include" really the best we can do?
Similarly, if programmers run amok, you get nasty messes like HTML printed from Perl scripts, or VBScript included in HTML files. This is very hard to maintain.
When desktop publishing arrived, managers with no publishing experience were suddenly making decisions about typefaces and graphic design. There was a period where they lacked experience, and it showed in the results. The same thing happens now, perhaps amplified, as managers are required to make decisions about interaction and navigation with very little experience.
Ask anyone: they hate HTML. They want to be doing sexy multimedia on CD-ROMs, not cross-platform information delivery (or making front-ends to databases). The greatest asset of HTML is exactly what they hate. But then, if they had been able to make money at CD-ROMs, they wouldn't be working on the web.
The new publishing is so different that very few people have much experience with it.
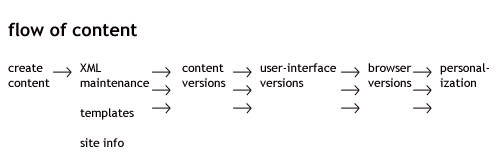
The main difference is maintenance. In the new publishing, you must maintain the content over time, and you must maintain one set of source files from which scripts (not HTML galley-slaves) generate multiple output versions.
Yes, we will separate the content from the user-interface, and we will create templates separately, and we will automate the merging of content and template.
The most fundamental difference is that we will be maintaining the content over time.
The new publishing's infrastructure must make content maintenance easy.
To a great extent, this is what the push to XML is about.
The elements of maintaining the content:
Content creators should be shielded from tags. But they do need to use the right "styles" (a la Word), and so the word processor needs to be able to
With the content stripped bare, HTML documents are fairly easy to understand and modify. A writer or editor would be better off making changes than trying to coordinate with an "HTML tagger".
Inadequate source control makes web publishing much more difficult than it has to be. Web publishing is done by teams, and when one person edits a file, no one else should be able to edit that file. HTML files are small, so locking is a very good thing.
Each person maintaining files should have an entirely separate work area. This insulates workers from changes others make until the changes are tested and approved.
Wrapped up in source control, version control is equally important. Each new version of a site may take time to prepare. Before the new version can be released, changed may need to be made to the current version.
HTML can become quite complicated when used for page layout. The goal in formatting the source should be to make it easy to read and understand. Some things that can help: comments identifying sections, useful whitespace, lower-case tags are more readable than upper case.
Since all of the content will flow through templates, the maintainability of the templates becomes a serious concern. The desire to separate content from interface extends to separating interface from the script. In an ideal case, the templates are kept in whole files where the designers can work with them visually. Perhaps several template chunks are stored in a single file so it is easy for a designer to see how they interact.
We might generate multiple versions of content, each with multiple user-interfaces (for different devices or bandwidths), perhaps further differentiating for incompatible browsers and browser versions. Finally there could be a personalization layer.